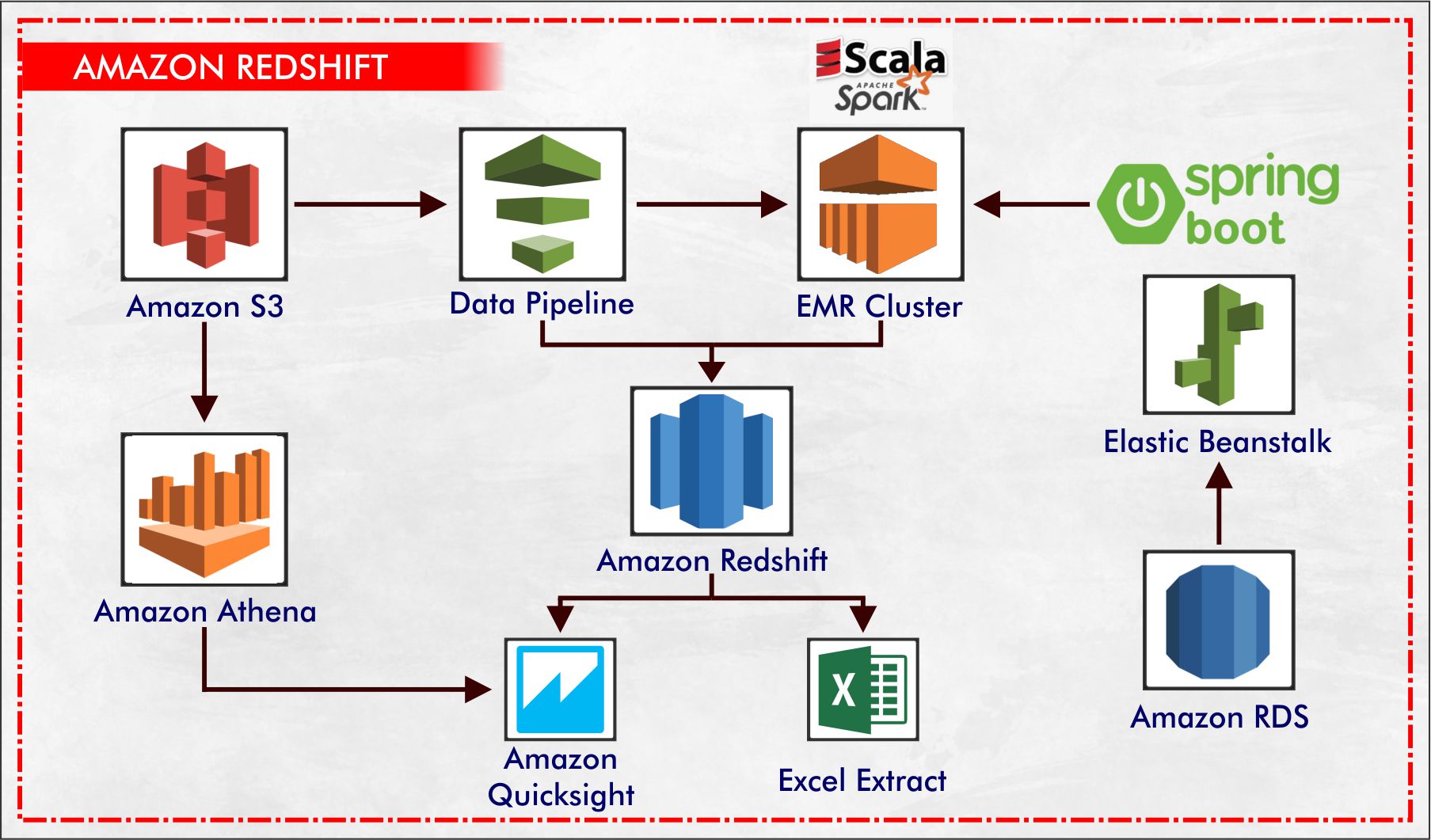
Amazon Redshift which is very well known as the most popular and fastest cloud data warehouse. Further, we can explain Amazon Redshift as a fully managed, cloud-based, petabyte-scale data warehouse service by Amazon Web Services (AWS). The database used in Redshift is RDBMS which is Relational Data Base Management System, so it is easily compatible with other RDBMS applications.
One can initially start with just gigabytes of data and may scale it to petabyte or more. This helps you to use your data to acquire new insights for your business and customers, in short, it is a perfect solution to collect and store all your data and further enables you to analyze it with help of various business intelligence tools to acquire new insights for your business & customers. Amazon Redshift ranks 1st for being the world’s fastest cloud data warehouse and that too at a low price.
Following are Prons and Cons for Redshift:
Prons:
a) Redshift is exceptionally fast, we can experience 50-100x speedup over Hive.
b) If we reserved for 3 years then, of course, the price is very low.
c) When it comes Massive Storage Capacity Redshift offers considerable a high storage capacity. A basic config can be extended to petabytes.
Cons:
a) When it comes Redshift then we cant insert uniqueness on inserted data. So if you have written or distributed data on Redshift you will need it to arrange it yourself, which can be done by application layer or via data. deduplication method.
b) Amazon Redshift needs a good understanding with regards to Sort key and distribution keys because both keys decide how data is stored and indexed on all redshift nodes.
c) Here loading data can be tricky as most of the time whenever you load data into Redshift which is mostly done via copy command. Still, there are lots of nuances regarding how to copy command work as you will need to master it.